실제 개발자가 Kafka를 사용하는 경우 이 내부 메커니즘이 필수적으로 필요한 내용은 아니다. 다만 어떻게 동작하는지 알아둔다면 Kafka를 운영하면서 튜닝이 필요한 부분을 보다 빨리 캐치하거나 감을잡기 위한 목적으로 이 글을 보기 바란다.
무엇에 대해 알아볼 것인가
내부 메커니즘 챕터를 통해서 크게 아래의 세가지 항목에 대해 알아볼 예정이다
- 카프카 복제(replication)가 동작하는 방법
- 카프카가 프로듀서와 컨슈머의 요청을 처리하는 방법
- 카프카가 스토리지를 처리하는 방법
Kafka Cluster 알고 넘어가기
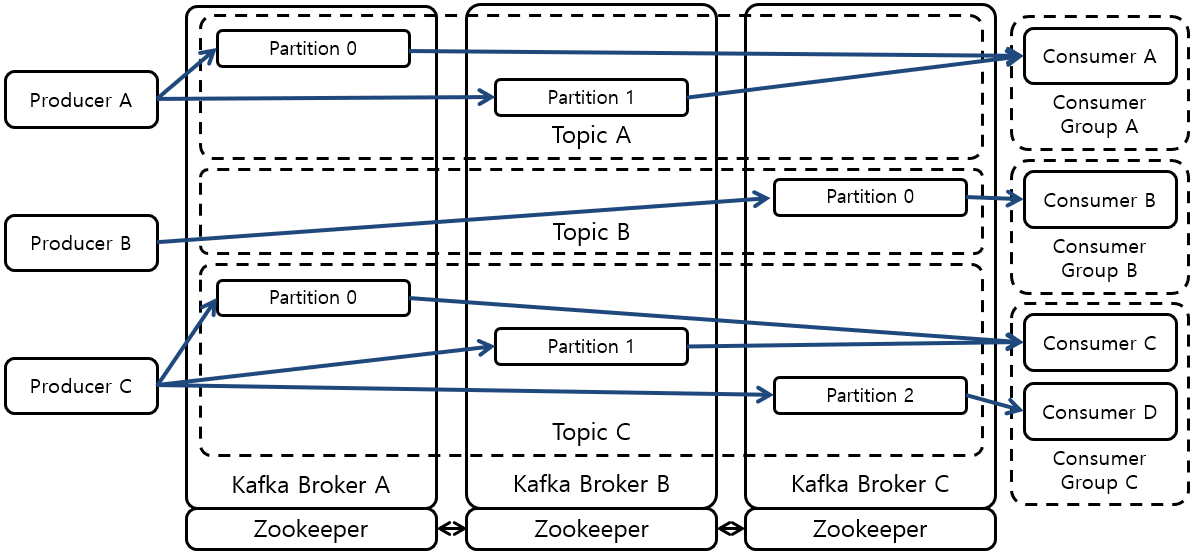
Kafka Broker는 일반적으로 Load Balancing 및 HA (High Availability)를 위해서 다수의 Node 위에서 Cluster를 이루어 동작한다.
| Broker | Message를 수신, 관리, 전송하는 Kafka의 핵심 Server이다 |
| Zookeeper | Cluster를 이루는 각 Kafka Broker의 동작 상태를 파악하고 상태 정보를 Producer 및 Consumer에게 전달 한다. |
| Producer | Kafka Cluster으로부터 Message를 전달하려는 Topic의 Partition 위치를 파악한 다음, Partition이 있는 Kafka Broker에게 직접 Message를 전달한다. Producer는 하나의 Topic에 다수의 Partition이 있는경우 기본적으로 Round-robin 순서대로 Message를 전달할 Partition을 선택한다. 만약 다른 Partition 선택 알고리즘이 필요하면, Producer 개발자는 Kafka가 제공하는 Interface를 통해 Partition 선택 알고리즘을 직접 개발 및 적용할 수 있다. |
| Consumer | Consumer도 Producer와 유사하게 Kafka Cluster으로부터 Message를 전달 받으려는 Topic의 Partition 위치를 파악한 다음, Consumer는 Partition이 있는 Kafka으로부터 Message를 직접 전달 받는다. |
Kafka Cluster는 Partition을 최대한 각 Node에 분산시켜 Load Balancing을 수행하고 Message 처리량도 높인다. Kafka Cluster를 구성하면 일부의 Kafka Broker가 죽어도 Producer와 Consumer는 Kafka를 계속 이용할 수 있지만 Message 손실을 막을 수 없다. 이러한 Message 손실을 막기위해 필요한 기법이 Replication이다.
주키퍼
카프카에서는 주키퍼를 사용해 클러스터 멤버인 브로커들의 메타 데이터를 유지 관리한다.
주키퍼의 최상위 노드를 /kafka-main 이라고 가정하면 아래와 같은 znode들이 구성된다
| /kafka-main/controller | 카프카 클러스터의 컨트롤러 정보가 저장됨 |
| /kafka-main/brokers | 브로커 ID 정보는 /brokers/ids에 토픽 정보는 /brokers/topics에 저장됨 |
| /kafka-main/config | 토픽의 설정 정보가 저장됨 |
| /kafka-main/consumers | 컨슈머의 파티션 오프셋 정보가 저장됨(카프카 버전 0.8 까지만 존재함. 0.9 부터는 __consumer_offsets라는 토픽에 저장됨) |
좀 더 자세히 들어가기 전에 주키퍼에 대해 간단히 알고 가자
| 주키퍼(zookeeper) | 파일 시스템처럼 트리구조로 데이터를 저장하고 사용함. |
| znode | zookeeper에서 데이터를 저장하는 노드를 가리킴. znode 이름 앞에는 /(슬래시)를 붙이고 디렉터리처럼 경로를 사용해 각 노드의 위치를 식별함 |
| 임시 노드 | 노드를 생성한 클라이언트가 연결되어 있을 때만 존재함. 연결이 끊어지면 자동으로 삭제됨 |
| 영구 노드 | 클라이언트가 삭제하지 않는 한 계속 보존됨 |
| Watch 기능 | znode의 상태를 모니터링 함(자식 노드들의 추가, 삭제, 데이터 변경을 감지하여 콜백 호출) |
주키퍼를 이용해 브로커를 관리하는 흐름
- 모든 카프카 브로커는 고유 식별자(ID)를 가짐
- 브로커 프로세스는 시잘될 때 마다 주키퍼의 /brokers/ids에 임시 노드로 자신의 ID를 등록함
- 만일 동일한 ID로 브로커를 시작하려고 하면 에러 발생함(ID는 브로커의 구성 파일에서 설정되거나 자동으로 생성됨)
- 브로커가 추가 혹은 삭제되거나 주키퍼와의 연결이 끊어지면 /brokers/ids에 등록한 임시노드는 자동으로 삭제됨
- 주키퍼에서 노드가 삭제될 때 watch 기능을 통해 카프카 컴포넌트들은 이를 감지 할 수 있음(리플리카 내역을 통해 중단된 브로커 정보들을 다시 이어갈 수 있음)
컨트롤러
- 카프카 브로커 중 하나이다
- 파티션 리더를 선출하는 책임이 있다
- 클러스터에서 시작하는 첫 번째 브로커가 컨트롤러가 된다
컨트톨러가 선정되는 방법
클러스터에서 시작하는 첫 번째 브로커는 /controller에 임시노드를 생성한다. 사실 첫 번째로 올라온 브로커가 아니더라도 모든 브로커가 프로세스 시작할 때 /controller에 임시노드를 생성하려 시도하지만, 가장 첫번째로 올라온 친구가 먼저 선점했기에 '노드가 이미 존재한다'는 예외를 받으면서 'controller가 존재하구나'라는 사실을 알게 된다.
더불어 컨트롤러가 아닌 브로커들은 /controller 노드에 watch 기능을 걸어 노드의 변경을 감지 한다.
컨트롤러 fail-over
-컨트롤러 브로커가 중단되거나 주키퍼와 연결이 끊어지면 /controller에 생성한 임시노드가 삭제 됨
- /controller에 watch를 걸었던 다른 브로커들은 이 사실을 알게 되고 /controller에 임시노드 생성을 시도하게 됨
- 시도에 성공한 친구가 컨트롤러가 되고, 시도에 실패한 친구들은 다시 새로운 controller 노드로 watch를 설정 함
이 때, controller 노드의 세대 번호들을 함께 저장하게 된다. 따라서 변경 전의 컨트롤러와 혼동되지 않으며, 이전 세대 번호로 된 컨트롤러 메세지를 받으면 무시한다.
리더 파티션 선출
- 특정 브로커가 클러스터를 떠나면, 컨트롤러는 그 브로커가 리더로 할당되었던 모든 파티션들에게 새로운 리더를 선출해야할 필요성을 인지함
- 어느 친구들이 리더 파티션 선출이 필요한지 파티션들을 점검함
- 보통 리플리카 리스트에서 떠나간 브로커의 다음 순서에 있는 브로커의 파티션들을 리더로 선출한다
- 컨트롤러는 새로운 리더 파티션과, 팔로우 파티션들의 정보를 모든 브로커들에게 전송함
새로 결정된 각 파티션의 리더는 프로듀서와 컨슈머의 요청 처리를 시작해야 한다는 것을 알고 있으며, 팔로어들은 새로운 리더의 메시지 복제를 시작해야 한다는 것을 알고 있다
복제
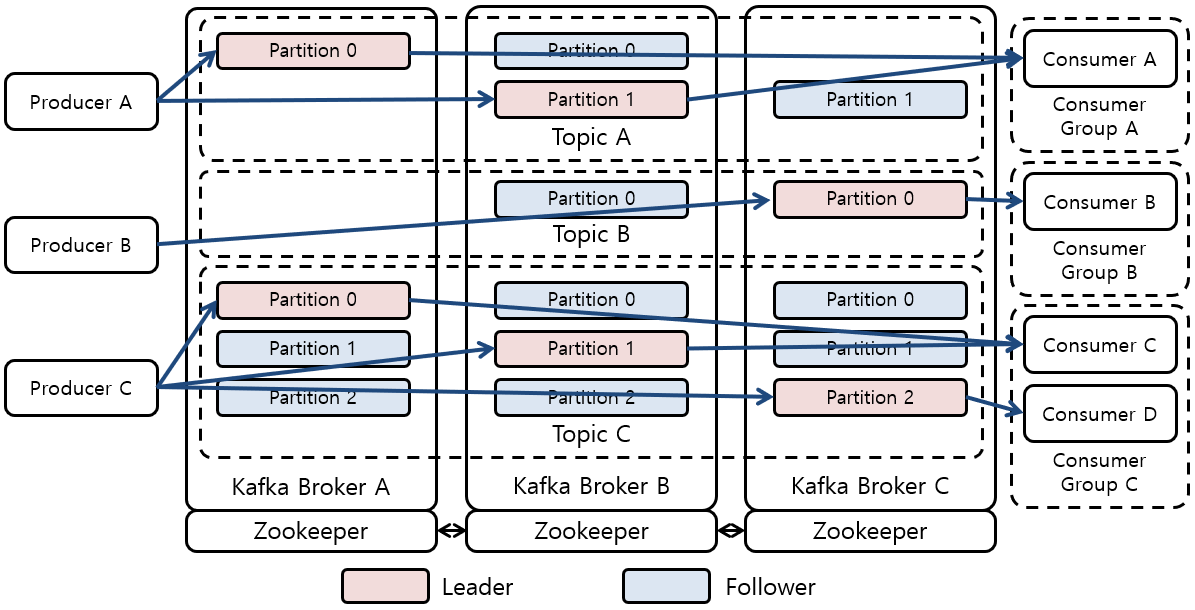
복제는 카프카 아키텍처의 핵심이다.
카프카의 데이터는 토픽으로 구성된다. 각 토픽은 여러 파티션에 저장될 수 있다. 또한 각 파티션은 다수의 리플리카를 가질 수 있다. 그리고 각 브로커는 서로 다른 토픽과 파티션에 속하는 수 백에서 많게는 수 천개까지의 복제본을 저장한다.
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic topic01
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic topic02

bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 2 –partitions 1 –topic topic01
bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 3–partitions 1 –topic topic02

리플리카에는 다음 두 가지 형태가 있다
| Leader replica | 각 파티션은 리더로 지정된 하나의 리더 리플리카를 갖는다. 일관성을 보장하기 위해 모든 프로듀서와 컨슈머의 요청은 리더를 통해서 처리된다. |
| Follower replica | 리더 리플리카를 제외한 나머지 리플리카를 가르킨다. 팔로어는 리더의 메시지를 복제하여 리더의 메시지와 동일하게 유지한다. 특정 파티션의 리더 리플리카가 중단되는 경우 팔로어 리플리카 중에서 새로운 리더를 선출한다 |
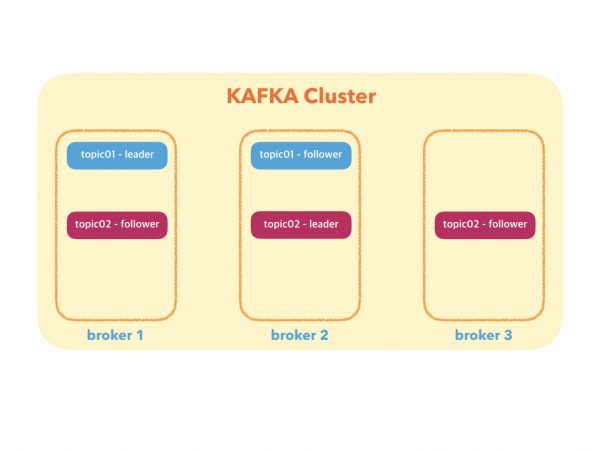
Follower가 Leader의 메세지를 동기화 하는 방법
리더와 동기화를 하기 위해 리플리카들은 리더에게 Fetch 요청을 전송한다. 이는 컨슈머가 메시지를 읽기 위해 전송하는 것과 같은 타입의 요청이다. 그리고 이에 대한 응답으로 리더는 리플리카들에게 메시지를 전송한다.
복제 지연을 판단하는 요소
1) 팔로어 리플리카가 10초 이상 메시지를 요청하지 않았을 경우
2) 요청은 했지만 10초 이상의 시간동안에도 가장 최근의 메시지를 복제하지 못하는 경우
위 경우, 해당 팔로어 리플리카는 리더가 장애가 발생 한 경우 새로운 리더로 선출할 자격을 잃게 된다.
ISR(in-sync-replica, 동기화 리플리카)
최신 메시지를 계속 요청하는 팔로어 리플리카를 뜻함

동기화 되지 않는다고 간주되기 전에, 팔로어가 비활성 상태가 될 수 있는 지연 시간은 replica.lag.time.max.ms 구성 매개변수로 제어할 수 있다.
'Kafka' 카테고리의 다른 글
| Kafka 모니터링 (0) | 2020.02.02 |
|---|---|
| Kafka 신뢰성 보장 (0) | 2020.01.27 |
| Kafka 내부 메커니즘 - 4)스토리지 (0) | 2020.01.20 |
| Kafka 내부 메커니즘 - 3)쓰기/읽기요청 (0) | 2020.01.20 |
| Kafka 내부 메커니즘 - 2)요청처리 (0) | 2020.01.20 |
